Aunque cada día veo que más gente hace pair programming, mob programming,… lo habitual es hacer pull request/merge request y tener que revisar el código (aka. code review) de los compañeros antes de integrarlo (lo de antes podemos discutirlo en otro post) en la rama principal. En este post vamos a tratar algunos puntos sobre cómo hacer code reviews con fundamento, sin opiniones, hablando de code smell.
Normalmente las pull request son una práctica que causa bastante fricción y a la que en mi opinión no le dedicamos la importancia que tienen: si hemos decidido hacer pull request antes de integrar, estas deberían ser el objetivo prioritario. El código de esta pull request/merge request está muy cerca de aportar valor. ¡Y qué no lo está haciendo porque no le estamos poniendo el cariño suficiente!
Hace tiempo ya estuvimos comentando en el blog Cómo llevar a cabo una code review y qué puntos tener en cuenta y que la code review involucra a lo más importante personas, por lo que la comunicación, los comentarios y la asertividad son importantes de cara a que podamos aportar feedback de calidad.

Para otro post dejaremos listar los que son en mi opinión los problemas principales de una code review, hoy, vamos a hablar un poco de cómo podemos mejorar nuestras code reviews como revisores. Vamos a partir de la base de que queremos aportar feedback accionable, de calidad y dejar de lado las opiniones y para ello nada mejor que conocer un poco más acerca de los code smells.
Los code smells son síntomas que podemos apreciar en nuestro código que posiblemente indican un problema mayor. Así que la idea es que cuando estemos revisando una pieza de código nos convirtamos en una especie de «doctores» del código para reconocer los síntomas y así poder tratar la enfermedad.
Aprendiendo buenas prácticas, conociendo code smells, ejercitando nuestra «toolbox» con haciendo katas, leyendo sobre patrones, haciendo Test Driven Development (TDD)… podemos incrementar esa «competencia inconsciente» que nos dice «parece que este código no esta bien del todo, le falta algo». Aunque hay que tener en cuenta que los code smells son un sintoma, una pista, sobre algo que podría estar mal. Por ello debemos tener en consideración que los code smells son subjetivos y varían según la persona que desarrolla, el lenguaje, el expertise,… entre otros factores. Pero hay una seria de code smells que pueden encontrarse con más frecuencia.
Los code smells pueden agruparse por tipos, así que haremos un repaso de los diferentes tipos, según https://refactoring.guru/es/refactoring/smells
Bloaters
Los bloaters son partes del código: métodos y/o clases que han aumentado a proporciones tan gigantescas que es difícil trabajar con ellos. Por lo general, estos olores no surgen de un día para otro, sino que se van acumulando a medida que vamos creando código, sobre todo cuando nadie pone el suficiente cariño para «mitigarlos». Así en este tipo de code smells nos podemos encontrar:
- Long Method: métodos largos. Lo ideal es que un método no haga más que una cosa, la S de SOLID
- Large Class: clases largas. Como long method pero aplicado a una clase
- Primitive Obsession: demasiados primitivos. Se usan tipos primitivos o arrays como parámetros de los métodos en lugar de utilizar objetos(aka. value objects)
- Long Parameter List: larga lista de parámetros. Si un método tiene más de 4 parámetros de entrada eso hace sospechar de que el método hace más de una cosa.
Si recordamos el post de object calisthenic casi todos esto «olores» se pueden detectar con alguna herramienta automática como PHPStan o similar.
Couplers
Todos los olores de este grupo contribuyen a un acoplamiento excesivo entre clases o muestran lo que sucede si el acoplamiento se reemplaza por una delegación excesiva.
- Feature Envy: envidia de funcionalidad. Es cuando un método accede a datos de otro objeto más que a los propios
- Inappropriate Intimacy: intimidad inapropiada. Son las clases que pasan demasiado tiempo juntas o las clases que interactúan de manera inapropiada.
- Incomplete Library Class: imagina que necesitamos un método que falta en la biblioteca, pero no estamos dispuestos o no podemos cambiar la biblioteca para incluir el método. El método termina agregando a otra clase.
- Message Chains: cadena de mensajes. Esto viene siendo cuando un objecto llama a otro objeto y este llama a otro objeto y este a otro…
- Middle Man: es justo lo contrario que «messge chains». O tambien puede deberse a que tenemos un armazón vacío que no hace más que delegar.
Dispensable
Prescindibles, estos olores nos indican que si eliminamos ese elemento nuestro código estará más limpio, más fácil de entender.
- Comments: Comentarios. Qué decir sobre esto, es mejor tener buenos nombres de variables, métodos, clases,…
- Duplicate Code: Código repetido en varios lugares.
- Data Class: es una clase que solo contiene métodos get/set. No tienen ninguna funcionalidad, ni opera con los datos que posee.
- Dead Code: Es código que no se ejecuta.
- Lazy Class: Son clases que no hacen lo suficiente o que no tienen razón de ser.
- Speculative Generality: Son métodos que no se usan, que lo mismo se crearon para el futuro, a mi parecer viene a ser lo mismo que el dead code.
¿Qué hacemos ahora?
Ahora que ya conocemos los code smells es necesario saber que hacemos con ellos. La idea es que cuando tengamos una pull request delante (o cuando estamos delante de nuestro propio código) seamos capaces de identificar estos code smells.En la pull request podemos hacer comentarios menos «opinionados» y con más fundamento. En vez de fijarnos en el nombre de una variable variable o en cuestiones que un analizador de código puede detectar, podemos fijarnos en otras cosas: ¿porqué esa clase es tan larga? ¿Parece que hay «message chain» en esta parte? o ¿crees que esto es feature envy? Con esto haremos que nuestras code reviews tengan un poco más de fundamento y nos ayudará a entender porqué la persona ha hecho este cambio o por qué no.
Véamoslo con este ejemplo; https://github.com/jeslopcru/curso-refactoring-php/tree/master/01-refactoring es la kata VideoStore de Uncle Bob. La idea es que dan esta PR donde alguien ha creado la funcionalidad statement() que devuelve por el terminal el historico de alquileres de un cliente:
Viendo este código creo que podemos identificar unos cuantos smells:
- Long method: el propio método statement
- large class: la clase customer, teniendo un método tan largo es una clase larga
- comments: hay varios comentarios en el código como en las lineas 12,36,…
- feature envy: a lo mejor la clase customer no debería de encargarse de calcular los rentedPoints
- message chains: linea 13 o linea 44 vemos que hay llamadas encadenadas
Estoy seguro de que se me escapan algunos code smells, pero si en una Pull Request comenzamos a dar feedback menos opinionado: este nombre de variable no me gusta, o podrías hacer esto con una arrow function,.. y más basado en creo que esto podríamos mejorarlo así. O por qué no intentamos esta otra aproximación para evitar este sme
Subiendo de nivel
Una vez que ya hemos detectado los code smell solo nos queda solucionarlos. ¿Cómo lo hacemos? Pues es sencillo en la web de Treataments que nos indica como podemos tratar el code smell.
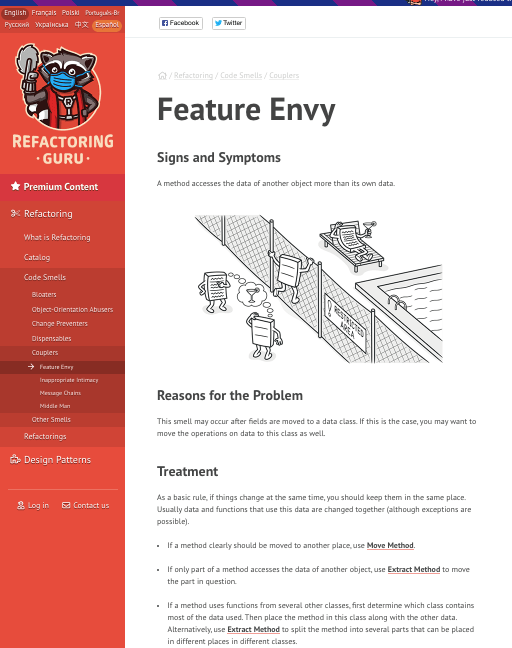
Por ejemplo para el caso de Feature envy tenemos un tratamiento que puede ser mover método o extraer método. Con esto solucionaremos el code smell y nuestro código estará más limpio.
Conclusiones
Conocer code smell y saber identificarlos nos ayudará a nosotros como desarrolladores cuando estamos escribiendo código. También nos ayudará a la hora de hacer una code review. Pero como todo, no hay que obsesionarse, hay veces que estos code smell puede que sean necesarios, que no sean tan «olorosos» o que haya otras partes del código que necesiten más atención. El saber identificarlos nos ayudará a tener conversaciones más sanas en una pull request para mejorar como equipo.
Todo ese post está inspirado en una sesión de Pedro M. Santos en la Barcelona Software Crafters.







Comenta la entrada