
Somos desarrolladores de software, tenemos que leer código gran parte de nuestro día, tenemos que usar código legado y tenemos que mantenerlo, incluso añadir nuevas funcionalidades. ¿Cómo lo hacemos? ¿Cómo abordamos cambios en legacy code de manera eficiente? Pues no tengo ni idea, pero sí sé que si tengo una buena caja de herramientas cerca mi trabajo será más sencillo. Por eso en este post vamos a llenar nuestra caja de herramientas con algunas técnicas que nos ayudarán a trabajar un poco mejor con legacy code. No se trata de usarlas todas siempre, sino de tenerlas a mano para cuando nos hagan falta.
Hotspot analysis
Ya sabemos que la mejor manera de acabar con el legacy es ir paso a paso, partido a partido, estamos en una maratón y tenemos que ir mejorando progresivamente: añadiendo pruebas, haciendo refactoring seguro, extrayendo funcionalidad, eliminando funcionalidad,… al final el tiempo es nuestro mejor aliado.
¿Por dónde empezamos?
Existen herramientas como code climate o SonarQube que pueden darnos una idea aproximada de en que punto estamos y cuál es la cantidad de deuda. Estas nos dan informes detallados de donde están los problemas más graves, pero cuidado: ¡Ir a los problemas graves es un error! al menos en un primer momento. Tenemos que priorizar. El simple hecho de que una parte del código tenga una métrica pésima, no significa que tengamos que ir primero a ella, tenemos que combinar este informe de deuda con las partes más cambiadas de nuestro código. Esto es llamado Churn
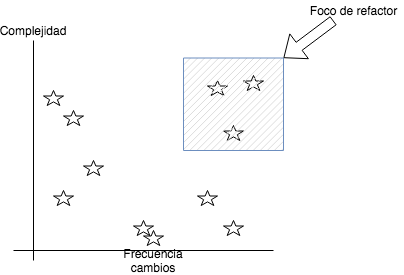
Pensémoslo, si hay código que es un lío, pero no lo hemos tocado en 2 años, ¿a quién le importa? Vamos a centrarnos en estos puntos del recuadro y poco a poco aprenderemos más sobre la aplicación, el negocio, la infraestructura,… y podremos afrontar los nuevos retos que se nos presenten.
Una manera sencilla de ver los archivos más modificados en git es haciendo algo como esto:
git log --format=format: --name-only --since=12.month \
| egrep -v '^$' \
| sort \
| uniq -c \
| sort -nr \
| head -50Cruzando datos o usando herramientas como Code Climante o similar podremos tomar decisiones más inteligentes y de verdad invertir esfuerzo en donde más nos compense.
Otras herramientas que pueden sernos útiles para cruzar estos datos son churn-php , code-forensics o codescene.
Mikado Method
Esta técnica es efectiva cuando tenemos un objetivo claro, o cuando queremos saber cuanto nos llevaría hacer un refactor «grande» y no queremos perdernos por el camino.
Lo primero es coger lápiz y papel o algo como https://excalidraw.com/ para anotar. Ahora lo primero que hacemos es escribir el objetivo y rodearlo con 2 círculos. Si para realizar ese objetivo necesitamos otra tarea: hacemos un git reset de lo que llevamos, la anotamos en otro circulo y empezamos de nuevo.
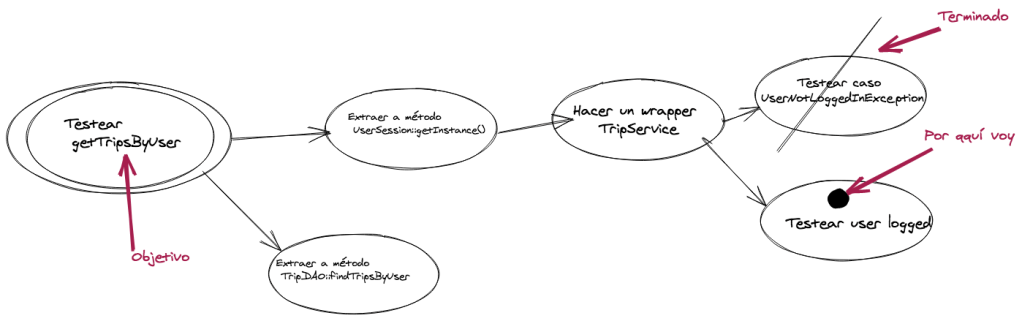
En algún momento llegaremos a un paso que podamos hacer sin problemas. Lo hacemos, lo tachamos y cogemos otra tarea.
La idea de este método es obtener una imagen de todas las dependencias, con este esquema podremos elegir los refactors más sencillos«menos dependientes» para poder ganando confianza y conocimiento del código, para más adelante poder ir mejorando el resto del código.
Este método sirve para no perder el foco de por donde vamos y cuanto nos queda. Del mismo modo con este método también podemos tener un análisis de cuanto nos costaría llevar a cabo un objetivo.
Mikado no solo sirve para refactorizar, sino que también nos ayuda no estresarnos, porque solo tenemos en la cabeza lo que estamos haciendo en este momento, no tenemos que recordar todo. Quien me conoce sabe que hago muchas veces la metáfora de la «mochila» que vamos cargando a medida que avanzamos por el camino, por lo que es importante tener la mochila lo más vacía posible.
Una de los errores más comunes a la hora de refactorizar es que nos «vamos enfangando». Es decir, queremos arreglar algo que está mal, pero entramos en otro método y nos cuenta de otro smell muy claro que podemos limpiar. Nos ponemos con este nuevo smell y nos damos cuenta de que tenemos que tocar allí,… esto es lo que se llama efecto túnel. Usando Mikado, evitamos ese efecto, porque nos centramos en la tarea que tenemos que hacer y si encontramos algo nuevo solo tenemos que anotarlo.
Over committing
Como ya hemos comentado antes, cuando trabajamos con legacy code es fácil perder el foco. O peor aún, llegar a un camino sin salida y no poder volver atrás porque «perdemos» demasiados cambios que si funcionan.
Tenemos que tener un enfoque más seguro, podemos apodarlo «guardar partida». La idea es tener <<puntos de control>> a los que volver si llegamos a un camino sin salida. Aquí es donde le sacamos partido a git, vamos a ir creando puntos de control cada vez que llegamos a un punto donde hemos conseguido algo.
Aquí podemos tomar un enfoque práctico, por ejemplo un script que haga un commit cada 5 minutos o podemos si usamos mikado ir haciendo commit cada vez que una tarea esté resuelta.
En mi caso optaría por algo parecido a lo 2º, es decir, ir poco a poco haciendo commits cada vez que vamos alcanzando hitos. Poniendo buenos mensajes de commits para saber que estoy haciendo con la historia.
La mejor manera de acostumbrarnos a hacer commits más pequeños es haciendo katas y poniendo un timer que haga reset cada 5 minutos.
Katas
Hacer cambios en código de producción, con pocos tests, donde ese código nos da de comer,… puede ser arriesgado a veces. Por eso debemos practicar, igual que Rafa Nadal entrena cada día, nosotros debemos hacer algo parecido.
Trabajar con Legacy Code es una skill que se aprende. Leer código «sucio», sin documentación es algo que podemos desarrollar.
En nuestro código de producción tenemos mucha complejidad y no controlamos al 100% que es lo que puede pasar, quizás sea buena idea tener un playground. Un lugar que controlemos y donde podamos intentar esa técnica que hemos leído en el libro «working effectively with legacy code», u obligarnos a hacer commits más pequeños, probar técnicas de testing como snapshop testing,…
Esta es una pequeña recopilación de katas sobre refactoring https://github.com/jeslopcru/refactoring-katas-php las podemos encontrar en cualquier lenguaje. Algunas de mis preferidas son:
- Trip Service Kata: de mis preferidas, ya que aprendemos a inyectar dependencias. Simula llamadas a una BD y tenemos que aprender a hacer tests sobre ese código sin llamar a la BD.
- Trivia Kata: un código legacy a tope, donde podemos aprender la técnica «Golden Master»
- Gilded-rose: un clásico para empezar con esto del refactoring.
Sobre katas hay un monton por Internet, si queréis estar al día o conocer nuevas katas Emily Bache tiene muchísimas.
Approval Testing
Esta técnica parece mágica y como todo poder hay que usarla con responsabilidad. Es una forma de escribir test para luego poder refactorizar el código.
La técnica se basa en generar una salida de la que podamos crear una «foto», ayudarnos de la cobertura de código para ver que hemos cubierto todo el código con tests y añadir mutation testing para verificar los «snapshot que hemos creado.
Podemos encontrar más información con otros nombres como: Characterisation Test, Golden Rule o Snapshot testing.
En PHP tenemos librerías como spatie/phpunit-snapshot-assertions o KigaRoo/snapshot-testing para crear snapshots. Para la cobertura de código XDebug es casi el standar por defecto. Para el mutation testing tenemos librerías como infection/infection, aunque la forma más sencilla de ver si nuestros test tienen una buena red de seguridad es comentando alguna linea suelta y ejecutando los tests. Si los test siguen en verde, tenemos que seguir trabajando con ellos.
Una de las ventajas de esta técnica es que no tenemos ni siquiera que leer el código para saber que está haciendo, nuestro objetivo es tener un buen snapshot para empezar a refactorizar de forma segura.
Aunque este tipo de test no son para siempre, sino solo cuando estamos inmersos en modificar un código legacy, una vez que empecemos a darle cariño a ese código tendremos que crear tests más a medida (unit testing, integration,,…). El Approval testing es temporal.
Architecture Decision Records (ADR)
Normalmente cuando estamos trabajando con Legacy code tenemos un problema de fondo que es la falta de contexto.
Cuando no sabemos porque se ha optado por una solución, se ha escogido una arquitectura o una pieza de infraestructura. Siempre entramos en dilemas de si cambiar esa pieza, mantenerla, que ventajas/desventajas existen con cada decisión,… a veces podemos ver el «git blame» y preguntar, otras incluso hacer arqueología de «git log» para saber cuando se añadió, pero todo esto conlleva un esfuerzo, un tiempo y a veces no es nada fácil.
Hay una técnica que parece obvia pero que pocos equipos usan y esa técnica es escribe un documento con la solución escogida, alternativas con sus pros y contras, ponle una fecha, básicamente describe el porqué escogiste esta solución y listo.

A esto se le llama Architecture Decision Records. Aquí tienes por ejemplo ADR del gobierno británico https://github.com/ministryofjustice/form-builder/tree/master/decisions
Como sabemos, lo difícil no es solo hacer este documento, sino tenerlo controlado, compartido, visible para el resto del equipo. Es un buen hábitoque fomentemos el hecho de escribir documentación como esta para que todo el equipo estemos al día de las decisiones.
Si te interesa el tema, hay algunas utilidades como npryce/adr-tools creada por el coautor de «Growing Object-Oriented Software, Guided by Tests» (un gran libro, por cierto).
Conclusiones
Trabajar con legacy code supone a veces mucha presión, un cambio puede hacer que todo se rompa sobre todo cuando no sabemos hacer «rollback». Aprendiendo técnicas como esta, aliviamos un poco esa presión y afrontamos esos cambios en el legacy code de otra manera, poco a poco con seguridad. Con seguridad, porque ya tenemos una serie de herramientas que nos ayudan durante el proceso y hacen que nuestras decisiones sean más consecuentes y meditadas. Pasaremos a divertirnos con ese código que al principio nos daba tanta pereza. Invertir tiempo en tener una buena caja de herramientas en mi opinión es una buena decisión de cara al futuro. Técnicas como estas no caducan, no son como la última librería JS o la versión 8.3 del framework de turno.
¿Qué técnicas conoces? ¿Cuál añadirías? ¿Cuál de estas has usado y te ha servido? mejor aún, ¿Cuál has usado y no te sirvió?¿Por qué?







Comenta la entrada